Data Lake Development: Unlocking the Power of Raw Data
In today’s data-driven world, the ability to effectively store, process, and analyze vast amounts of raw data is crucial for gaining actionable insights and making informed decisions. Data lakes provide a powerful solution for managing large volumes of unstructured and structured data. This blog will explore the fundamentals of data lake development, its benefits, and best practices to ensure you maximize the utility and accessibility of your data.
What is a Data Lake?
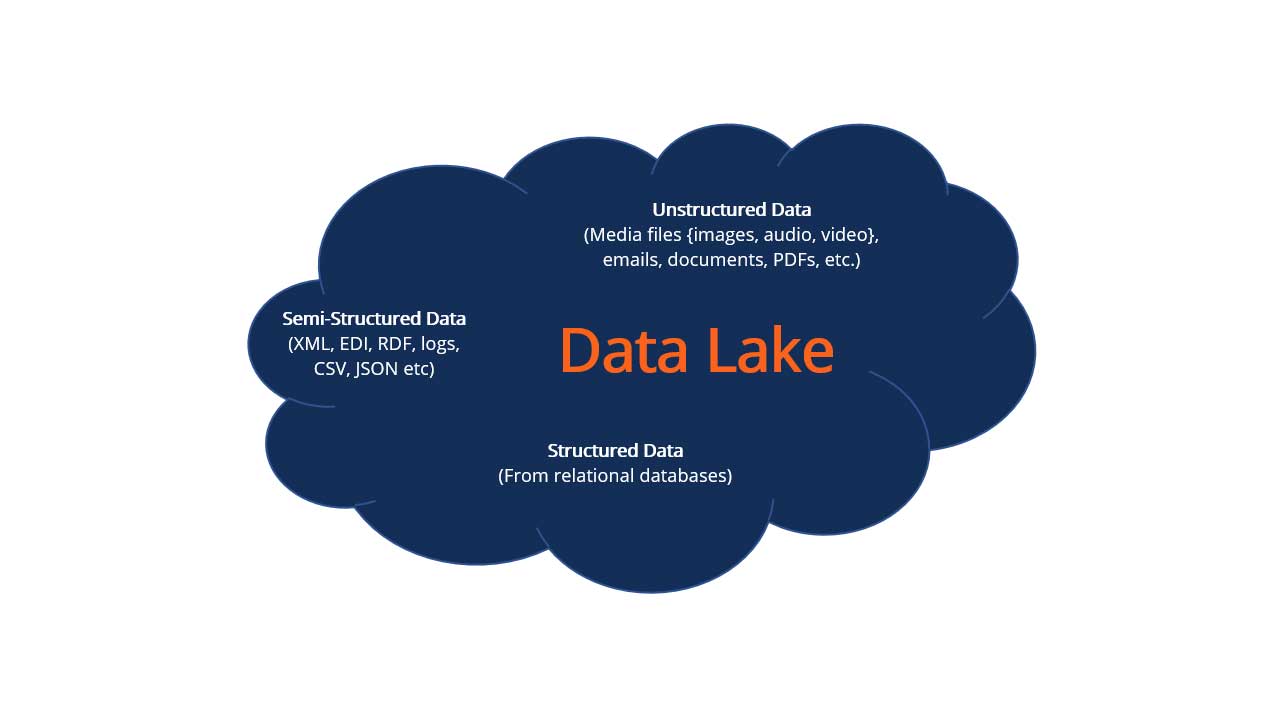
A data lake is a central hub where you can store both structured and unstructured data in large quantities. Unlike traditional databases, data lakes store data in its raw form, which means you can preserve the original format and metadata. This flexibility allows for more comprehensive data analysis and retrieval.
Key Benefits of Data Lakes
1. Scalability
Data lakes are built to manage and process vast quantities of data. As your data grows, you can scale your data lake infrastructure without the need for major redesigns. This scalability ensures that you can manage and analyze data efficiently even as your business expands.
2. Cost-Effectiveness
Storing raw data in a data lake is generally more cost-effective compared to traditional databases. Data lakes utilize distributed storage systems and commodity hardware, which reduces the overall cost of data management.
3. Flexibility and Versatility
With a data lake, you can store various types of data, including structured, semi-structured, and unstructured data. This versatility allows for comprehensive data analysis and integration, making it easier to uncover insights from diverse data sources.
4. Enhanced Data Accessibility
Data lakes provide a single source of truth for all your data. This centralization makes it easier for teams to access and analyze data, leading to better collaboration and more informed decision-making.
Best Practices for Data Lake Development
1. Define Your Data Lake Strategy
Before implementing a data lake, it’s essential to define your strategy. Determine what types of data you will store, how you will manage data quality, and how you plan to secure your data. A well-defined strategy will guide your data lake development and ensure its success.
2. Ensure Data Governance
Implement robust data governance practices to manage data quality, security, and compliance. Establish clear policies for data ingestion, storage, and access to maintain the integrity and confidentiality of your data.
3. Use Metadata for Data Management
Leverage metadata to enhance data discovery and management. Metadata provides context about the data, including its source, format, and usage. Effective metadata management helps users find and understand data more easily.
4. Implement Data Security Measures
Protect your data lake with strong security measures. Use encryption, access controls, and regular audits to safeguard sensitive data and ensure compliance with data protection regulations.
5. Optimize for Performance
Ensure that your data lake is optimized for performance. Implement indexing, partitioning, and data caching strategies to improve query performance and reduce latency.
Conclusion
Data lake development offers a robust solution for managing and analyzing large volumes of raw data. By implementing best practices and leveraging the benefits of data lakes, businesses can enhance their data accessibility, scalability, and cost-efficiency. With a well-designed data lake, you can unlock the full potential of your data and drive informed decision-making across your organization.
FAQs
1. What types of data can be stored in a data lake?
Data lakes can store structured, semi-structured, and unstructured data. This includes data from various sources such as databases, logs, social media, and more.
2. How does a data lake differ from a data warehouse?
A data lake stores data in its raw, unprocessed form, whereas a data warehouse stores data that has been processed and structured for analysis. Data lakes offer more flexibility in terms of data types and formats.
3. What are the common tools used for data lake development?
Common tools for data lake development include Apache Hadoop, Apache Spark, Amazon S3, Microsoft Azure Data Lake, and Google Cloud Storage. These tools help with data storage, processing, and analysis.
4. How do I ensure data quality in a data lake?
You can ensure data quality through robust data governance practices, including data validation, cleansing, and monitoring. Implementing metadata management and data lineage tracking also helps maintain data quality.
5. Can a data lake be integrated with existing data systems?
Yes, you can integrate a data lake with existing data systems such as data warehouses, CRM systems, and analytics tools. This integration allows for seamless data flow and more comprehensive analysis.