Hadoop Development and Implementation: Harnessing the Power of Hadoop for Distributed Data Processing
In today’s data-driven world, businesses need robust solutions to manage and analyze massive volumes of data efficiently. Hadoop, an open-source framework, offers a powerful way to achieve distributed data processing. This blog explores the benefits of Hadoop development and implementation, shedding light on how it can transform your data handling and provide timely insights for your business.
What is Hadoop?
Hadoop is an open-source framework that enables distributed storage and processing of large datasets using a cluster of commodity hardware. Developed by the Apache Software Foundation, it is designed to scale up from a single server to thousands of machines, each offering local computation and storage.
Key Components of Hadoop
1. Hadoop Distributed File System (HDFS): HDFS is the primary storage system of Hadoop, designed to store large files across multiple machines. It breaks files into blocks and distributes them across the cluster, providing fault tolerance and high throughput.
2. MapReduce: This is the processing engine of Hadoop. It divides tasks into smaller chunks and processes them in parallel across the cluster. The MapReduce framework efficiently handles vast amounts of data by performing operations such as sorting and filtering.
3. YARN (Yet Another Resource Negotiator): YARN is the resource management layer of Hadoop. It manages resources across the cluster and schedules applications, ensuring optimal utilization of resources.
4. Hadoop Common: This is a set of shared utilities and libraries used by other Hadoop modules. It provides essential services and tools for the functioning of the Hadoop ecosystem.
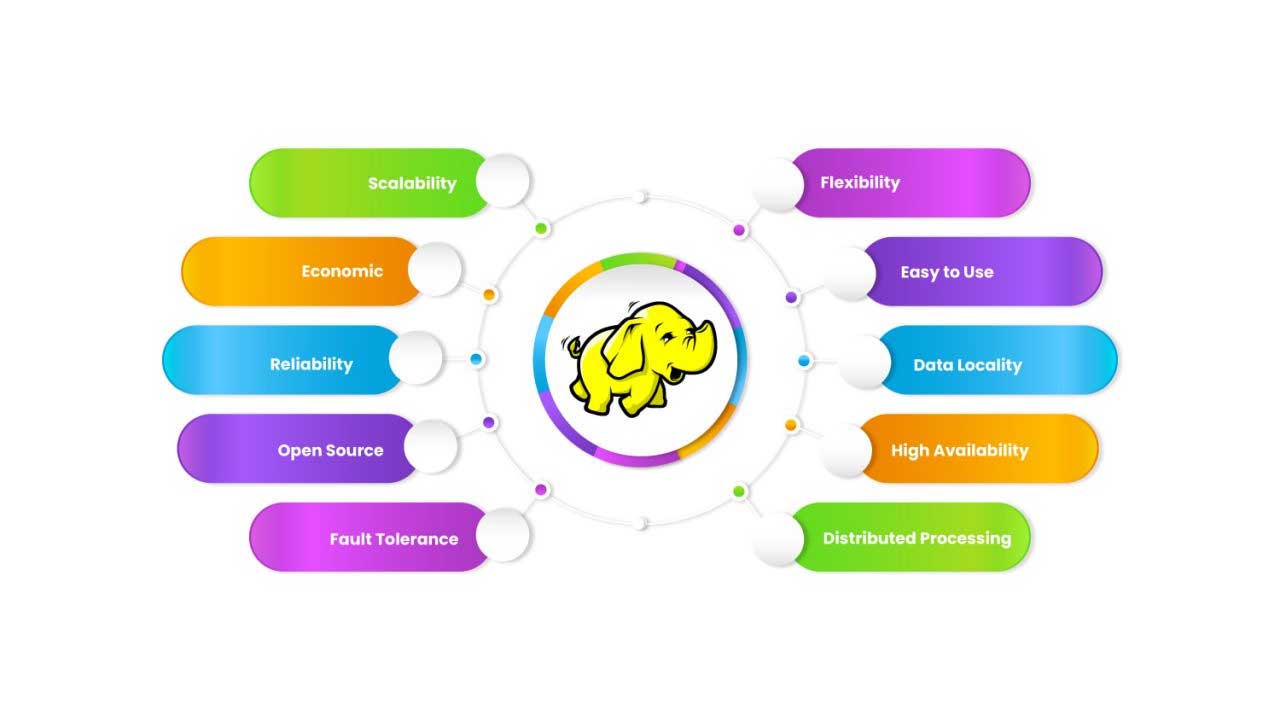
Benefits of Hadoop Development
1. Scalability
Hadoop’s architecture is inherently scalable. It can handle growing amounts of data by simply adding more nodes to the cluster. This scalability ensures that businesses can expand their data processing capabilities as needed without major infrastructure changes.
2. Cost-Effectiveness
Hadoop leverages commodity hardware, which is less expensive compared to traditional high-performance servers. This cost-effective approach allows organizations to build a powerful data processing infrastructure without breaking the bank.
3. Fault Tolerance
Hadoop’s distributed nature ensures fault tolerance. Data is replicated across multiple nodes, so if one node fails, the system can continue to operate using the replicated data. This redundancy minimizes data loss and enhances reliability.
4. Flexibility
Hadoop supports various data formats, including structured, semi-structured, and unstructured data. This flexibility allows organizations to process diverse data types and gain insights from a wide range of sources.
5. Speed
The parallel processing capabilities of Hadoop’s MapReduce framework enable fast data processing. By dividing tasks into smaller units and processing them simultaneously, Hadoop significantly reduces the time required to analyze large datasets.
Implementation of Hadoop: Key Steps
1. Requirement Analysis
Before implementation, it’s crucial to understand the specific needs of your business. This involves assessing the volume and types of data you handle, your processing requirements, and your goals for using Hadoop.
2. Cluster Setup
Setting up a Hadoop cluster involves configuring hardware and software components. This includes installing Hadoop on multiple nodes, setting up HDFS, and configuring YARN for resource management.
3. Data Ingestion
Data ingestion is the process of loading data into Hadoop. You can use various tools such as Apache Flume, Apache Sqoop, or custom data ingestion scripts, depending on your data sources.
4. Development and Testing
Develop and test MapReduce jobs or other Hadoop applications that process your data. This involves writing code to perform specific data operations and testing it to ensure it meets your performance and accuracy requirements.
5. Deployment
Once tested, deploy your Hadoop applications to the cluster. This includes configuring job schedules, monitoring performance, and making adjustments as needed to optimize processing efficiency.
6. Monitoring and Maintenance
Ongoing monitoring and maintenance are essential to ensure the smooth operation of your Hadoop cluster. This involves tracking performance metrics, managing resources, and addressing any issues that arise.
Conclusion
Hadoop offers a powerful solution for distributed data processing, enabling businesses to handle vast amounts of data efficiently and cost-effectively. By harnessing the capabilities of Hadoop, organizations can achieve scalable, reliable, and fast data processing, ultimately gaining valuable insights to drive their business forward. Whether you are looking to implement Hadoop from scratch or enhance your existing setup, leveraging expert Hadoop development and implementation services can help you unlock the full potential of your data.
FAQs
What is Hadoop used for?
Hadoop is used for processing and analyzing large datasets across a distributed computing environment. It is ideal for tasks such as data warehousing, real-time analytics, data mining, and more.
How does Hadoop ensure data security?
Hadoop provides several security features, including authentication, authorization, and data encryption. You can implement Kerberos authentication, use Apache Ranger for access control, and encrypt data at rest and in transit to enhance security.
Can Hadoop be used for real-time data processing?
Although Hadoop’s MapReduce framework handles batch processing, other components and tools within the Hadoop ecosystem, such as Apache Storm and Apache Flink, support real-time data processing.
How does Hadoop compare to traditional databases?
Hadoop differs from traditional databases in that it is designed for handling large volumes of unstructured or semi-structured data across distributed systems. Traditional databases are often optimized for structured data and transactional processing.
What are some common Hadoop use cases?
Common use cases for Hadoop include data warehousing, log processing, data lakes, recommendation systems, fraud detection, and social media analytics. Its versatility enables businesses to apply it to a wide range of industries and applications.







